


Was ist passiert? Bereits vor einigen Jahren zeichnete sich ab, dass der Grund für Verbesserungen der KI nicht unbedingt in brillanten menschlichen Tricks, sondern viel eher in der massiven Skalierung von Daten, mehr Rechenpower und grösseren Modellen zu suchen ist. Richard S. Sutton hielt diese Erkenntnis 2019 in seinem vielbeachteten Essay «The Bitter Lesson» fest, und in den Jahren 2022 und 2023 hat sich diese Erkenntnis bewahrheitet: OpenAI erschuf mit GPT-3.5/4 mithilfe massiver Rechenpower, grosser Datenmengen und makellosem Engineering ein Modell, das Menschen überall auf der Welt begeistert. In Form von ChatGPT für alle zugänglich, erleichtert dieses generalistische Modell die Arbeit für viele unterschiedliche Berufe.
Und das ist erst der Anfang. Bereits jetzt ist klar, dass die nächste Generation dieser Modelle nicht nur Text, sondern auch Bilder, Kamera-Feeds, Audiodateien oder gar Sensorik von Robotern verarbeitet. Gleichzeitig ziehen die grossen Player im Bereich KI mit ähnlichen Modellen nach – Google stellte sein Modell PaLM 2 Ende Mai mittels API zur Verfügung, und bereits jetzt gibt es Open-Source-Modelle, die der Performance von GPT-4 und Co. nahekommen. Nicht nur für Endbenutzerinnen und -benutzer ist die Entwicklung von solchen Large Language Models (LLMs) wie GPT-4 interessant. Auch für die Machine Learning Engineers von ti&m verändert sich die Arbeitswelt damit. Waren Projekte im Bereich Machine Learning und KI bisher oft anspruchsvoll und teilweise mit hohen Aufwänden verbunden, ermöglichen LLMs ein völlig neues Vorgehen. Ein konkretes Beispiel: Wollte ein Kunde aus der Versicherungsbranche eine Software bauen, die eingehende Schadensfälle automatisch an die richtigen Abteilungen leitet, musste er noch vor drei Jahren ein umfangreiches Projekt in Angriff nehmen:
- Es mussten genügend Daten für das Training und Testing eines ML-Modells beschafft oder erschaffen werden.
- Verschiedene Modell-Architekturen mussten trainiert und getestet werden.
- Das trainierte Modell musste in eine klassische Software integriert werden.
Oft wurde dieser Prozess in mehreren Iterationen bis zum Erreichen der gewünschten Qualität durchgeführt. Nur mit diesem beachtlichen Aufwand war es möglich, komplexe Probleme mithilfe von KI zu lösen. Mit dem Einzug von LLMs verändern sich die Möglichkeiten für solche Projekte. Anstatt selbst Daten zu sammeln und Modelle zu trainieren, reicht es heute oft, mithilfe von Prompt Engineering in einem sogenannten Zero-Shot Learning die richtigen Fragen zu stellen. Dazu zwei Beispiele aus Projekten:
Projekt 1 «Kundenkommunikation mit LLMs analysieren»
Beinahe jedes grössere Retail-Unternehmen sammelt durch die Kommunikation mit Kundinnen und Kunden wie Telefongesprächen, E-Mails oder Chats eine grosse Menge an Daten. Die Analyse dieser Daten kann einen grossen Mehrwert liefern: Sind die Kunden zufrieden mit den Produkten? Wenn nicht: Was sind die Gründe? Welche Bedürfnisse beschäftigen die Kundinnen und Kunden im Moment? In wie vielen Gesprächen wird wie häufig über Thema XY gesprochen?
Diese und weitere Fragen lassen sich heute mit verhältnismässig kleinem Aufwand beantworten. In einem ersten Schritt müssen dafür Telefongespräche transkribiert werden. Dafür existieren seit Jahren KI-Modelle, die mehr oder weniger zuverlässig Sprache in Text übersetzen. Gerade für Nischensprachen wie Schweizerdeutsch war die Qualität aber oft mangelhaft oder nur unter Einsatz von grossem Aufwand zu erreichen. Mit modernen KI-Modellen wie Whisper (Open Source, entwickelt von OpenAI) können heute auch Gespräche auf Schweizerdeutsch in sehr hoher Qualität in schriftdeutschen Text transkribiert werden. Selbst verhältnismässig schwierige Dialekte funktionieren auch ohne spezifisches Training problemlos. Ist die orale Kommunikation verschriftlicht, lässt sie sich sehr einfach mit GPT-4 analysieren. Dabei müssen, je nach Use Case, die richtigen Prompts entwickelt werden. Für eine einfache Zusammenfassung eines Gesprächs reicht dabei ein simpler Prompt wie «Bitte fasse das folgende Gespräch in drei Sätzen kurz und prägnant zusammen». Für andere Use Cases werden die Prompts etwas umfangreicher.
Mithilfe von zusätzlichen Prompt-Engineering-Tricks kann zudem sichergestellt werden, dass die Antworten des Modells wahrheitsgetreu und möglichst fehlerfrei sind.
Aus technischer Sicht wird ein solches Projekt damit in erster Linie zu einem Integrationsprojekt:
- Wie lässt sich das interne Telefonsystem mit Speech-to-Text-Modellen wie Whisper verbinden?
- Wo und wie lange werden sensitive, transkribierte Gespräche sicher gespeichert?
- Wie wird GPT-4 integriert (z. B. via Azure)?
- Wie werden grosse Mengen von Gesprächen zu Spitzenzeiten effizient, vielleicht beinahe in Echtzeit, verarbeitet?
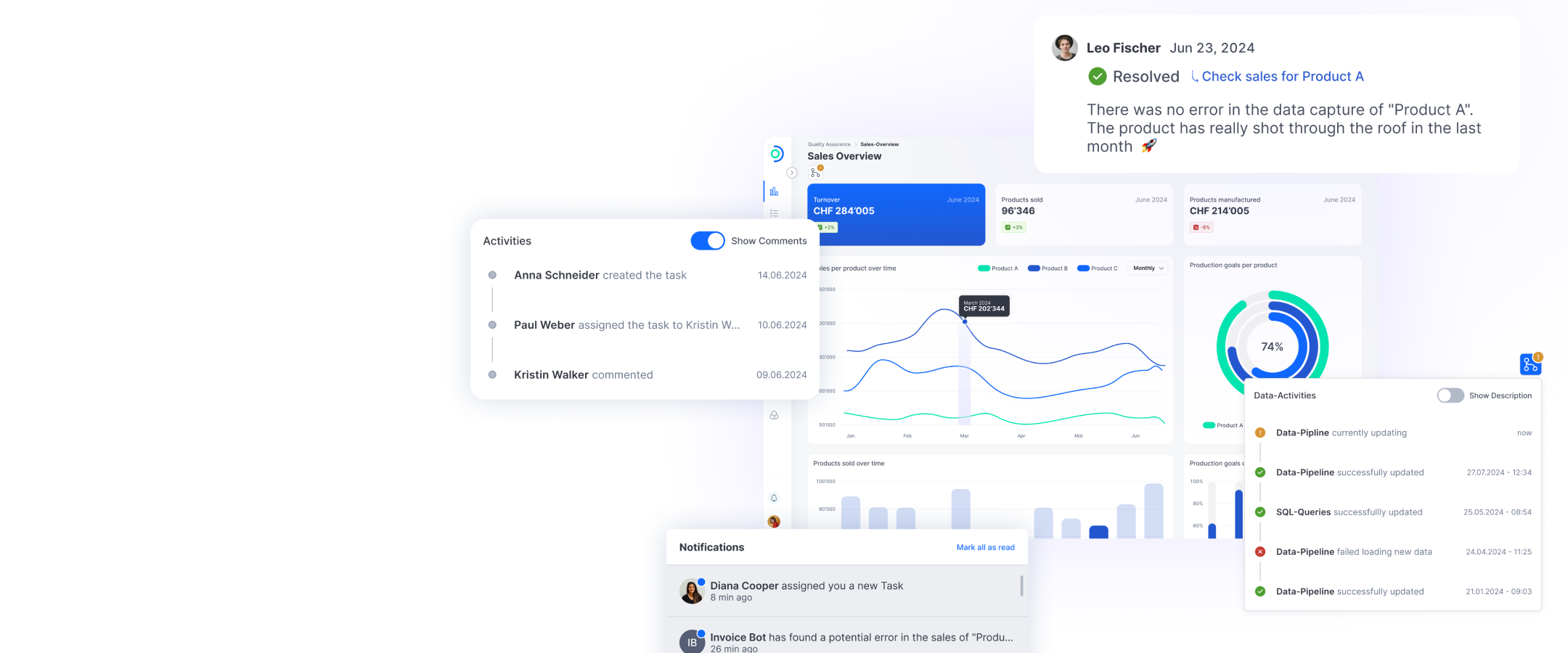
Bei solchen Integrationsprojekten können Technologiepartner wie ti&m mit interdisziplinären Teams aus KI-, Software- und DevOps-Expertinnen und -Experten unterstützen.
Projekt 2 «KI-Assistent: ein ChatGPT für Unternehmensdaten»
Das zweite konkrete Projektbeispiel für LLMs kommt dem originalen ChatGPT sehr nahe: Was, wenn ein Unternehmen seinen Kundinnen und Kunden einen wirklich smarten KI-Assistenten anbieten könnte, der konkrete Antworten zu Produkten und Services liefern kann? Der Zugriff auf kunden-spezifische Informationen hat und damit komplexe Fragen wie «Wie viel Geld habe ich letztes Jahr für die Produkte X und Y ausgegeben?» beantworten kann? Das wird möglich, wenn smarte LLMs wie GPT-4 mit Unternehmensdaten kombiniert werden (siehe Architekturübersicht). In einem ersten Schritt werden sämtliche relevanten Firmendaten indexiert. Ob die Daten als lose Dokumente wie PDFs und Word-Dokumente in einem Ordner oder als strukturierte Daten in einer Datenbank hinterlegt sind, ist dabei nicht relevant. Die indexierten Daten werden dann in einem Suchindex gespeichert, oft in Form von sogenannten Embeddings. Stellt nun eine Benutzerin oder ein Benutzer eine konkrete Frage wie «Wie viel kostet Service XY im Jahr XZ», werden zu- erst mithilfe von sogenannten Retriever- oder Question-Answering-Modellen die Dokumente gesucht, welche eine potenzielle Antwort auf die Frage enthalten. Das können 5 oder auch 50 Dokumente sein. Wichtig ist, dass sehr schnell eine grosse Menge an irrelevanten Dokumenten aussortiert werden kann. Nun werden diese wenigen Dokumente zusammen mit der Frage und eventuell weiteren Informationen an GPT-4 gesendet. GPT-4 liest die mitgeschickten Dokumente, kombiniert die relevanten Fakten und schreibt eine kohärente Antwort mit Verweis auf die Quelldokumente. Die Antwort und die Quellen werden nun vom KI-Assistenten an die Benutzerin oder an den Benutzer weitergegeben. Das entsprechende Medium – ein Chatbot auf der Webseite, eine Integration in MS Teams oder WhatsApp oder sogar eine automatische Ant- wort via E-Mail – kann je nach Präferenz festgelegt werden.
KI-Kickstart mit ti&m
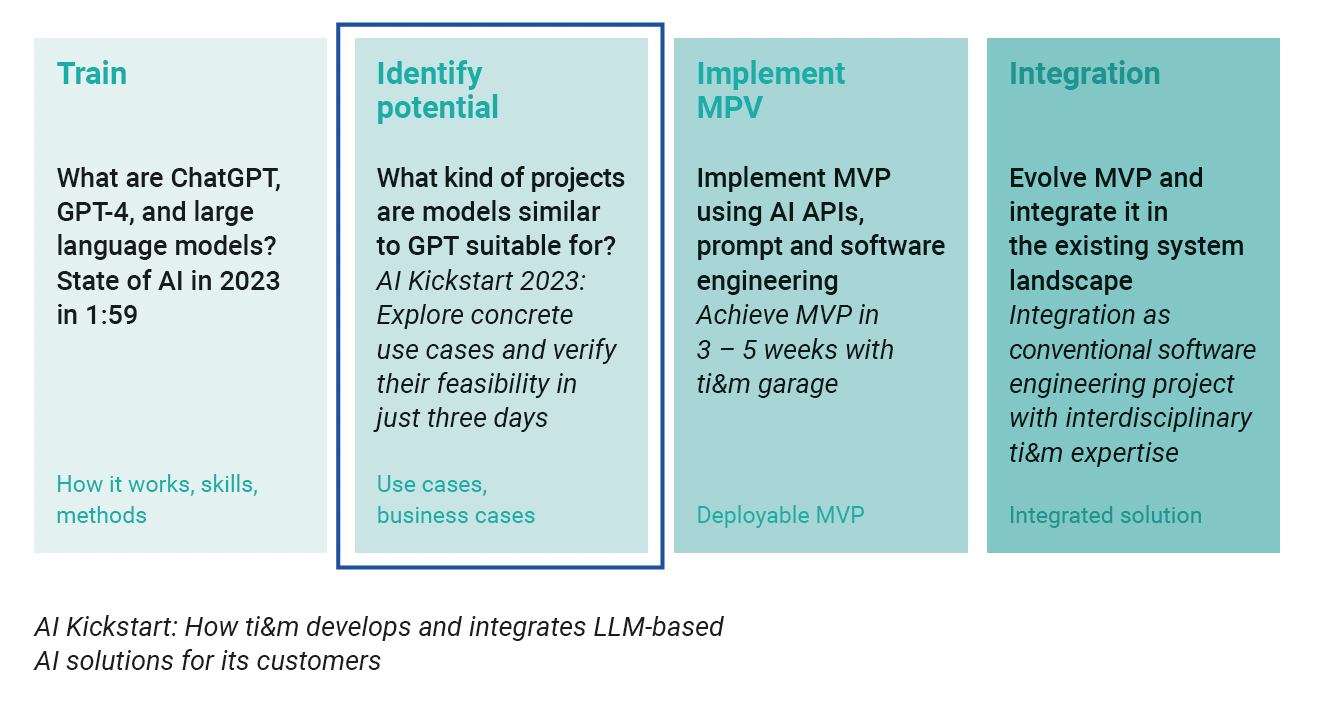
Die Möglichkeiten von KI wachsen von Tag zu Tag, und damit auch potenzielle Anwendungsfälle für verschiedene Bereiche und Branchen. Wie bei jeder technologischen Entwicklung gilt auch hier: Man muss nicht alles sofort und auf einmal machen. Sicher ist, dass durch KI Arbeitsprozesse effizienter gestaltet und neue Geschäftsmodelle erschlossen werden können. Mit einem starken Technologiepartner sollten diese Opportunities identifiziert und Use Cases umgesetzt werden, die schnell einen spürbaren Mehrwert bieten. Mit dem KI-Kickstart bietet ti&m genau das: In diesem dreitägigen Workshop geben unsere Expertinnen und Experten eine Einführung in die Technologie von KI und ermitteln gemeinsam mit unseren Kunden konkrete Use Cases. Nach dem Workshop setzen unsere Teams in drei bis fünf Wochen die erste Version einer funktionsfähigen Lösung um (ein Minimum Viable Product), die in die bestehende Systemlandschaft des Kunden integriert wird. So unterstützt ti&m seine Kunden bei der schrittweisen Adaption von KI für ihr Business.

